En este blog podrás encontrar información referente a este lenguaje de programación web.
jueves, 5 de diciembre de 2013
Introduccion
En este blog podrás encontrar información referente a este lenguaje de programación web.
Historia
Lenguaje de XML
XML proviene de un lenguaje inventado por IBM en los años setenta, llamado GML (Generalized Markup Language), que surgió por la necesidad que tenía la empresa de almacenar grandes cantidades de información. Este lenguaje gustó a la ISO, por lo que en 1986 trabajaron para normalizarlo, creando SGML (Standard Generalized Markup Language), capaz de adaptarse a un gran abanico de problemas. A partir de él se han creado otros sistemas para almacenar información.
En el año 1989 Tim Berners Lee creó la web, y junto con ella el lenguaje HTML. Este lenguaje se definió en el marco de SGML y fue de lejos la aplicación más conocida de este estándar. Los navegadores web sin embargo siempre han puesto pocas exigencias al código HTML que interpretan y así las páginas web son caóticas y no cumplen con la sintaxis. Estas páginas web dependen fuertemente de una forma específica de lidiar con los errores y las ambigüedades, lo que hace a las páginas más frágiles y a los navegadores más complejos.
 Otra limitación del HTML es que cada documento pertenece a un vocabulario fijo, establecido por el DTD. No se pueden combinar elementos de diferentes vocabularios. Asimismo es imposible para un intérprete (por ejemplo un navegador) analizar el documento sin tener conocimiento de su gramática (del DTD). Por ejemplo, el navegador sabe que antes de una etiqueta <div> debe haberse cerrado cualquier <p> previamente abierto. Los navegadores resolvieron esto incluyendo lógica ad hoc para el HTML, en vez de incluir un analizador genérico. Ambas opciones, de todos modos, son muy complejas para los navegadores.
Otra limitación del HTML es que cada documento pertenece a un vocabulario fijo, establecido por el DTD. No se pueden combinar elementos de diferentes vocabularios. Asimismo es imposible para un intérprete (por ejemplo un navegador) analizar el documento sin tener conocimiento de su gramática (del DTD). Por ejemplo, el navegador sabe que antes de una etiqueta <div> debe haberse cerrado cualquier <p> previamente abierto. Los navegadores resolvieron esto incluyendo lógica ad hoc para el HTML, en vez de incluir un analizador genérico. Ambas opciones, de todos modos, son muy complejas para los navegadores.
Se buscó entonces definir un subconjunto del SGML que permita:
Mezclar elementos de diferentes lenguajes. Es decir que los lenguajes sean extensibles.
La creación de analizadores simples, sin ninguna lógica especial para cada lenguaje.
Empezar de cero y hacer hincapié en que no se acepte nunca un documento con errores de sintaxis.
Para hacer esto XML deja de lado muchas características de SGML que estaban pensadas para facilitar la escritura manual de documentos. XML en cambio está orientado a hacer las cosas más sencillas para los programas automáticos que necesiten interpretar el documento.
Estructura de un Documento XML
Estructura de un Documento XML

La tecnología XML busca dar solución al problema de expresar información estructurada de la manera más abstracta y reutilizable posible. Que la información sea estructurada quiere decir que se compone de partes bien definidas, y que esas partes se componen a su vez de otras partes. Entonces se tiene un árbol de trozos de información. Ejemplos son un tema musical, que se compone de compases, que están formados a su vez por notas. Estas partes se llaman elementos, y se las señala mediante etiquetas.
Una etiqueta consiste en una marca hecha en el documento, que señala una porción de éste como un elemento. Un pedazo de información con un sentido claro y definido. Las etiquetas tienen la forma <nombre>, donde nombre es el nombre del elemento que se está señalando.
A continuación se muestra un ejemplo para entender la estructura de un documento XML:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE Edit_Mensaje SYSTEM "Edit_Mensaje.dtd"> <Edit_Mensaje> <Mensaje> <Remitente> <Nombre>Nombre del remitente</Nombre> <Mail> Correo del remitente </Mail> </Remitente> <Destinatario> <Nombre>Nombre del destinatario</Nombre> <Mail>Correo del destinatario</Mail> </Destinatario> <Texto> <Asunto> Este es mi documento con una estructura muy sencilla no contiene atributos ni entidades... </Asunto> <Parrafo> Este es mi documento con una estructura muy sencilla no contiene atributos ni entidades... </Parrafo> </Texto> </Mensaje> </Edit_Mensaje>
Documentos Bien formados y Validados en XML
Los documentos denominados como «bien formados» (del inglés well formed) son aquellos que cumplen con todas las definiciones básicas de formato y pueden, por lo tanto, analizarse correctamente por cualquier analizador sintáctico (parser) que cumpla con la norma. Se separa esto del concepto de validez que se explica más adelante.
· Los documentos han de seguir una estructura estrictamente jerárquica con lo que respecta a las etiquetas que delimitan sus elementos. Una etiqueta debe estar correctamente incluida en otra, es decir, las etiquetas deben estar correctamente anidadas. Los elementos con contenido deben estar correctamente cerrados.
· Los documentos XML sólo permiten un elemento raíz del que todos los demás sean parte, es decir, solo pueden tener un elemento inicial.
· Los valores atributos en XML siempre deben estar encerrados entre comillas simples o dobles.
 ·
·
El XML es sensible a mayúsculas y minúsculas. Existe un conjunto de caracteres llamados espacios en blanco (espacios, tabuladores, retornos de carro, saltos de línea) que los procesadores XML tratan de forma diferente en el marcado XML.
· Es necesario asignar nombres a las estructuras, tipos de elementos, entidades, elementos particulares, etc. En XML los nombres tienen alguna característica en común.
· Las construcciones como etiquetas, referencias de entidad y declaraciones se denominan marcas; son partes del documento que el procesador XML espera entender. El resto del documento entre marcas son los datos «entendibles» por las personas.
Partes del Documento XML
Un documento XML está formado por el prólogo y por el cuerpo del documento así como texto de etiquetas que contiene una gran variedad de efectos positivos o negativos en la referencia opcional a la que se refiere el documento, hay que tener mucho cuidado de esa parte de la gramática léxica para que se componga de manera uniforme.
Prólogo
Aunque no es obligatorio, los documentos XML pueden empezar con unas líneas que describen la versión XML, el tipo de documento y otras cosas.
El prólogo de un documento XML contiene:

Una declaración XML. Es la sentencia que declara al documento como un documento XML.
Una declaración de tipo de documento. Enlaza el documento con su DTD (definición de tipo de documento), o el DTD puede estar incluido en la propia declaración o ambas cosas al mismo tiempo.
Uno o más comentarios e instrucciones de procesamiento.
EJEMPLO: <?xml version="1.0" encoding="UTF-8"?>
Cuerpo
A diferencia del prólogo, el cuerpo no es opcional en un documento XML, el cuerpo debe contener solo un elemento raíz, característica indispensable también para que el documento esté bien formado. Sin embargo es necesaria la adquisición de datos para su buen funcionamiento.
EJEMPLO: <Edit_Mensaje>
(...)
</Edit_Mensaje>
Elementos

Los elementos XML pueden tener contenido (más elementos, caracteres o ambos), o bien ser elementos vacíos.
Atributos
Los elementos pueden tener atributos, que son una manera de incorporar características o propiedades a los elementos de un documento. Deben ir entre comillas.
Por ejemplo, un elemento «estudiante» puede tener un atributo «Mario» y un atributo «tipo», con valores «come croquetas» y «taleno» respectivamente.
<Estudiante Mario="come croquetas" tipo="taleno">Esto es un día que Mario va paseando…</Estudiante>
Entidades predefinidas
Entidades para representar caracteres especiales para que, de esta forma, no sean interpretados como marcado en el procesador XML.
Ejemplo: entidad predefinida: & carácter: &.
miércoles, 4 de diciembre de 2013
XML Schemas
Introducción general
 El propósito del estándar XML Schemas es definir la estructura de los documentos XML que estén asignados a tal esquema y los tipos de datos válidos para cada elemento y atributo. En este sentido las posibilidades de control sobre la estructura y los tipos de datos son muy amplias.
El propósito del estándar XML Schemas es definir la estructura de los documentos XML que estén asignados a tal esquema y los tipos de datos válidos para cada elemento y atributo. En este sentido las posibilidades de control sobre la estructura y los tipos de datos son muy amplias.
Al restringir el contenido de los ficheros XML es posible intercambiar información entre aplicaciones con gran seguridad. Disminuye el trabajo de comprobar la estructura de los ficheros y el tipo de los datos.
XML Schema tiene un enfoque modular que recuerda a la programación orientada a objetos y que facilita la reutilización de código.
Los tipos de datos tienen en XML Schemas la función de las clases en la POO. El usuario puede construir tipos de datos a partir de tipos predefinidos, agrupando elementos y atributos de una determinada forma y con mecanismos de extensión parecidos a la herencia. Los tipos de datos se clasifican en función de los elementos y atributos que contienen.
Los tipos de datos en XML Schema pueden ser simples o complejos:
Definiciones de tipos simples.
Definiciones de tipos complejos.
XML Schemas incluye el uso de namespaces. Los "espacios de nombres" permiten definir elementos con igual nombre dentro del mismo contexto, siempre y cuando se anteponga un prefijo al nombre del elemento. El uso de namespaces también evita confusiones en la reutilización de código.
Los ficheros XML Schemas se escriben en el propio lenguaje XML.
Tipos simples
Tipos simples son aquellos que no tienen ni elementos hijos ni atributos.
Son tipos simples:
Tipos predefinidos de XML: string, double, boolean, etc.
List (lista de datos separados por espacios).
Union (tipo de dato derivado de la unión de tipos predefinidos).
Tipos complejos
Son tipos complejos aquellos que tienen elementos hijos y/o atributos.
Pueden tener nombre o ser anónimos. Si tienen nombre pueden ser reutilizados dentro del mismo XML Schema o por otros XML Schemas.
Es posible "mezclar" o combinar elementos y texto.
Ventajas de los Schemas frente a los DTDs
La necesidad de jerarquizar y estructurar correctamente la información, no sólo para almacenarla, sino también para acceder a ella, se ha convertido en una labor que ha cobrado especial relevancia en los últimos años, en los que se han producido importantes avances en este campo.
Pero las DTDs no satisficieron todas las necesidades inherentes a XML y pronto se vio necesario utilizar otros métodos más rigurosos y sofisticados para tratar la estructura y la semántica dentro de un documento XML. Así surgieron los Esquemas XML (XML Schema), como una forma de ampliación y mejora de las primitivas DTDs. Las DTDs y los Schemas son usados por losanalizadores sintácticos o parsers para comprobar si un documento XML es válido.
Así pues, vemos que para proceder a la estructuración o especificación formal dentro de un documento XML existen distintas soluciones, entre las que cabe destacar principalmente dos: lasDTDs y los XML Schemas. Pero veamos con más profundidad las diferencias entre la utilización de DTDs y Esquemas.
La Declaración de Tipo de Documento (DTD-Document Type Data):
Al definir el lenguaje XML ya nos referimos a la Definición del Tipo de Documento (Document Type Definition DTD) que, en resumen, cumple las siguientes funciones:
Una DTD especifica la clase de documento
Describe un formato de datos
Usa un formato común de datos entre aplicaciones
Verifica los datos al intercambiarlos
Verifica un mismo conjunto de datos
Una DTD describe
Elementos: cuáles son las etiquetas permitidas y cuál es el contenido de cada etiqueta
Estructura: en qué orden van las etiquetas en el documento
Anidamiento: qué etiquetas van dentro de cuáles

Los elementos de una DTD son los siguientes:
Elementos con “contenido ELEMENT”:
Un elemento tiene contenido ELEMENT, si solo puede contener a otros elementos, opcionalmente separados por espacios en blanco.
Elementos con “contenido TEXT”
Un elemento tiene contenido TEXT, si solo puede contener texto
(PCDATA = printable character data)
Elementos con “contenido MIXED”
Un elemento tiene contenido MIXED, si puede contener texto u otros elementos
Elementos con “contenido EMPTY”
Un elemento tiene contenido EMPTY, si no puede contener otros elementos
Y los atributos son los siguientes:
CDATA: texto
NMTOKEN: “abc...z0123..9-_:.” (tipo de lista)
NMTOKENS: NMTOKEN + espacios
ID: empezar con letra
IDREF: ser un ID
Así pues, la DTD especifica la clase de documento XML. Una DTD indica sólo qué elementos, atributos, etc; tiene un documento y cómo se anidan, pero no dice nada acerca de tipos de dato. El único tipo de dato que conoce es CDATA (texto plano), por tanto, las DTDs se quedan algo cortas y cuando se necesita algo más potente y rígido, se usa Schema
Recordemos que una DTD se puede guardar en un archivo de texto, como por ejemplo, en el archivo "list.dtd". Una DTD muy simple es la siguiente:
<!ELEMENT List (Item)+>
<!ELEMENT Item (#PCDATA)>
<!ATTLIST Item
id CDATA IMPLIED
color CDATA IMPLIED>
<!ELEMENT Separator EMPTY>
Veamos ahora el documento .xml que hace referencia a esa DTD:
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE list SYSTEM "list.dtd">
<List>
<Item>París</Item>
<Item>Madrid</Item>
<Separator />
<Item color="rojo">Londres</Item>
</List>
XML Schema:
 Al igual que las DTDs, los Schemas describen el contenido y la estructura de la información, pero de una forma más precisa. Los esquemas indican tipos de dato, número mínimo y máximo de ocurrencias y otras características más específicas.
Al igual que las DTDs, los Schemas describen el contenido y la estructura de la información, pero de una forma más precisa. Los esquemas indican tipos de dato, número mínimo y máximo de ocurrencias y otras características más específicas.
Según la Especificación del W3C XML Schema (http://www.w3.org/XML/Schema), los esquemas expresan vocabularios compartidos que permiten a las máquinas extraer las reglas hechas por las personas. Los esquemas proveen un significado para definir la estructura, contenido y semántica de los documentos XML.
Un esquema XML (XML schema) es algo similar a un DTD, es decir, define qué elementos puede contener un documento XML, cómo están organizados, y qué atributos y de qué tipo pueden tener sus elementos, pero la utilización de schemas ofrece nuevas posibilidades en el tratamiento de los documentos.
Por ejemplo, un schema nos permite definir el tipo del contenido de un elemento o de un atributo, y especificar si debe ser un número entero, una cadena de texto, una fecha, etc. Las DTDs no nos permiten hacer estas cosas.
Veamos un ejemplo de un documento XML, y su schema correspondiente:
<documento xmlns="x-schema:personaSchema.xml">
<persona id="fulanito">
<nombre>Fulano Menganez</nombre>
</persona>
</documento>
Como podemos ver en el documento XML anterior, se hace referencia a un espacio de nombres (namespace) llamado "x-schema:personaSchema.xml". Es decir, le estamos diciendo al analizador sintáctico XML (parser) que valide el documento contra el schema "personaSchema.xml".
El schema sería algo parecido a esto:
<Schema xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<AttributeType name='id' dt:type='string' required='yes'/>
<ElementType name='nombre' content='textOnly'/>
<ElementType name='persona' content='mixed'>
<attrubyte type='id'/>
<element type='nombre'/>
</ElementType>
<ElementType name='documento' content='eltOnly'>
<element type='persona'/>
</ElementType>
</Schema>
La ventaja de utilizar los schemas con respecto a los DTDs son:
- Usan sintaxis de XML, al contrario que los DTDs.
- Permiten especificar los tipos de datos.
- Son extensibles (esto es, permite crear nuevos elementos).
XSLT
 Al igual que XML, XSLT es un lenguaje de programación. Forma parte de la trilogía transformadora de XML, compuesta por las CSS (Cascading Style Sheets, hojas de estilo en cascada), que permite dar una apariencia en el navegador determinada a cada una de las etiquetas XML; XSLT (XML Stylesheets Language for Transformation , o lenguaje de transformación basado en hojas de estilo); y XSL:FO, (Formatting Objects, objetos de formateo), o transformaciones para fotocomposición, o, en general, para cualquier cosa que no sea XML, como por ejemplo HTML "del viejo" o PDF (el formato de Adobe).
Al igual que XML, XSLT es un lenguaje de programación. Forma parte de la trilogía transformadora de XML, compuesta por las CSS (Cascading Style Sheets, hojas de estilo en cascada), que permite dar una apariencia en el navegador determinada a cada una de las etiquetas XML; XSLT (XML Stylesheets Language for Transformation , o lenguaje de transformación basado en hojas de estilo); y XSL:FO, (Formatting Objects, objetos de formateo), o transformaciones para fotocomposición, o, en general, para cualquier cosa que no sea XML, como por ejemplo HTML "del viejo" o PDF (el formato de Adobe).
Los programas XSLT están escritos en XML, y generalmente, se necesita un procesador de hojas de estilo, o stylesheet processor para procesarlas, aplicándolas a un fichero XML.
El estilo de programación con las hojas XSLT es totalmente diferente a los otros lenguajes a los que estamos acostumbrados (tales como C++ o Perl), pareciéndose más a "lenguajes" tales como el AWK, o a otros lenguajes funcionales, tales como ML o Scheme. En la práctica, eso significa dos cosas:
No hay efectos secundarios. Una instrucción debe de hacer lo mismo cualquier que sea el camino de ejecución que llegue hasta ella. O sea, no va a haber variables globales (¡Cielos!), ni bucles en los que se incremente el valor de una variable, o tenga un test de fin de bucle, ni nada por el estilo. En realidad, esto no es tan grave, y se puede simular usando recursión, como se verá.
La programación está basada en reglas: cuando ocurre algo en la entrada, se hace algo en la salida. En eso, se parece al AWK, o a cierto estilo de programación en PERL, pero no en el resto de las cosas. Al fin y al cabo, no hay efectos secundarios.
SAX significa Simple API for XML; un filtro SAX trata un fichero XML como un canal (stream) sobre el cual se van aplicando transformaciones según se va leyendo. Para transformaciones simples tales como extraer un tipo de etiqueta determinada, y, de hecho, la mayoría de las incluidas en este tutorial, es mucho mejor usar un filtro SAX. El principal problema es que carecen de un lenguaje para describir esas transformaciones, y la sintaxis y aplicación depende totalmente del lenguaje en el que se trabaje. En Perl, por ejemplo, se puede usar XML::SAX, un módulo que permite hacer este tipo de transformaciones. Generalmente, en caso de ficheros muy grandes a los que haya que hacerle un procesamiento relativamente simple, SAX es una opción mejor, más rápida y con menos consumo de memoria.
En resumen, programar con las hojas XSLT (en inglés se les llama stylesheets o logicsheets) puede ser un poco frustante, pero cuando uno aprende a usarlas, no puede vivir sin ellas. En realidad, son la única alternativa cuando uno quiere adaptar un contenido descrito con XML a diferentes clientes (por ejemplo, móviles de diferente tamaño, diferentes navegadores), y la mejor alternativa cuando uno quiere procesar documentos XML (aunque haya otras: filtros SAX, expresiones regulares...). Otra alternativa, sobre todo si se está trabajando ya con un documento XML en forma de DOM (Document object model) es trabajar directamente sobre él. En este claso, de todas formas, se pueden usar transformaciones XSL, sólo que se aplicarán en memoria, en vez de leerlas desde un fichero.
Lo que consiguen las hojas de estilo es separar la información (almacenada en un documento XML) de su presentación, usando en cada caso las transformaciones que sean necesarias para que el contenido aparezca de la forma más adecuada en el cliente. Es más, se pueden usar diferentes hojas de estilo, o incluso la misma, para presentar la información de diferentes maneras dependiendo de los deseos o de las condiciones del usuario.
Aparte del hecho habitual de procesar documentos XML, XSLT es un lenguaje de programación, y por tanto se podría hacer cualquier cosa con ellas; incluso calcular la célebre criba de Eratóstenes o ejecutar un algoritmo genético. Pero a nosotros nos va a interesar más como simple herramienta de transformación de XML.
Actualmente hay varias versiones del estándar XSLT: la versión 1.0, que es la que implementan la mayoría de los procesadores, y se denomina "recomendación", es decir, para el consorcio W3, lo equivalente a un estándar, y la versión 2.0 , que, a fecha de 4 de noviembre del 2004, es un "working draft", o borrador de trabajo, que es el paso previo a un estándar. Algunos procesadores, tales como el Saxon, implementan ya esta última versión. Hay algunas diferencias importantes: el tratamiento uniforme de los árboles (técnicamente, se pueden convertir fragmentos de árboles de resultados en nodesets), uso de múltiples documentos de salida, y funciones definidas por el usuario que se pueden definir en XSLT, y no sólo en Java u otro lenguaje, como sucedía en estándares anteriores. .
Las convenciones que seguimos en los ejemplos son las siguientes: cada etiqueta XML en el documento XML van en diferente color, dependiendo de su posición en la jerarquía; en las hojas XSL, el código XML está en rojo, el código XSLT en verde, y el código que no es exclusivo ni de uno ni de otro, y que aparecerá tal cual en el documento final, en azul.
Para Windows, en sus diferentes versiones, hay dos herramientas que permiten editar XML y hojas de estilo XSLT, y aplicar directamente la una a la otra. Una de ellas es XMLSpy, que tiene un IDE muy bonito, pero que casca con relativa frecuencia. De hecho, he sido incapaz de aplicar una hoja de estilo a un documento XML. Otra opción es usar eXcelon Stylus, un peaso de programa, pero que sólo está disponible para WindowsNT/2000 (y no sé si XP); la versión 3.0 beta es gratuita para desarrolladores.
En realidad, para editar XML y XSLT no hace falta ningún editor especial, pero viene bien un editor de XML o incluso un entorno integrado que te ayude a indentar bien el código, e incluso a cerrar las etiquetas en el orden correcto, o te saque la etiqueta y atributos admisibles en cada momento en función del DTD. En ese sentido, si se trabaja en Windows, el mejor es el eXcelon Stylus; en Linux, se puede uno apañar bien con el XEmacs (que te valida usando un DTD, si es necesario).
Puedes leer mas aqui: http://geneura.ugr.es/~jmerelo/XSLT/
RSS

RSS es una forma muy sencilla para que puedas recibir, directamente en tu ordenador o en una página web online (a través de un lector RSS) información actualizada sobre tus páginas web favoritas, sin necesidad de que tengas que visitarlas una a una. Esta información se actualiza automáticamente, sin que tengas que hacer nada. Para recibir las noticias RSS la página deberá tener disponible el servicio RSS y deberás tener un lector Rss.
Si existen varias páginas web que te interesan que van actualizando sus contenidos y te gustaría mantenerte informado, un lector RSS te ahorrará mucho tiempo en esta tarea. Gracias al RSS, no tendrás que visitar cada una de las páginas web que te interesan para ver si han añadido o no algún artículo que te pueda interesar. Estas páginas te informarán a ti (a través de tu lector de RSS). Cuando ingreses a tu Lector RSS (o Rss Reader), estarás automáticamente informado sobre todas las novedades que se han producido en todas las páginas web que has dado de alta.
Leer mas sobre RSS: http://www.rss.nom.es/
Resumen
Para resumir podemos poder decir que el lenguaje de XML (eXtensible Markup Language) no es, como su nombre podría sugerir, un lenguaje de marcado. XML es un meta-lenguaje que nos permite definir lenguajes de marcado adecuados a usos determinados.
Este lenguaje es un mecanismo de vinculación a otros documentos XML. Funciona de forma similar a un enlace en una página Web, es decir, funciona como lo haría <a href="">, sólo que a href es un enlace unidireccional. Sin embargo, XLink permite crear vínculos bidireccionales, lo que implica la posibilidad de moverse en dos direcciones. Esto facilita la obtención de información remota como recursos en lugar de simplemente como páginas Web.
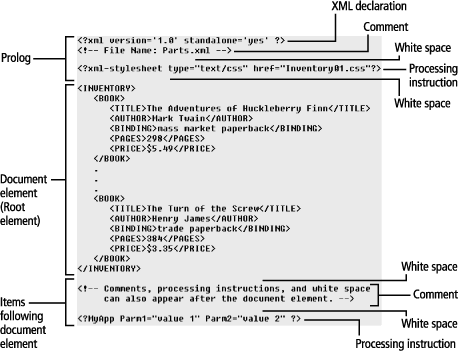
Estructura de un documento XML
La tecnología XML busca dar solución al problema de expresar información estructurada de la manera más abstracta y reutilizable posible. Que la información sea estructurada quiere decir que se compone de partes bien definidas, y que esas partes se componen a su vez de otras partes. Entonces se tiene un árbol de trozos de información. Ejemplos son un tema musical, que se compone de compases, que están formados a su vez por notas. Estas partes se llaman elementos, y se las señala mediante etiquetas.
Documentos XML bien formados y control de errores
Los documentos denominados como «bien formados» (del inglés well formed) son aquellos que cumplen con todas las definiciones básicas de formato y pueden, por lo tanto, analizarse correctamente por cualquier analizador sintáctico (parser) que cumpla con la norma.
Partes de un documento XML
Un documento XML está formado por el prólogo y por el cuerpo del documento así como texto de etiquetas que contiene una gran variedad de efectos positivos o negativos en la referencia opcional a la que se refiere el documento, hay que tener mucho cuidado de esa parte de la gramática léxica para que se componga de manera uniforme.
Las partes de un documento XML son:
- Prólogo
- Cuerpo
- Elementos
- Atributos
- Entidades predefinidas
- Secciones CDATA
- Comentarios
XSLT y RSS

XSLT o Transformaciones XSL es un estándar de la organización W3C que presenta una forma de transformar documentos XML en otros e incluso a formatos que no son XML. Las hojas de estilo XSLT - aunque el término de hojas de estilo no se aplica sobre la función directa del XSLT - realizan la transformación del documento utilizando una o varias reglas de plantilla. Estas reglas de plantilla unidas al documento fuente a transformar alimentan un procesador de XSLT, el que realiza las transformaciones deseadas poniendo el resultado en un archivo de salida, o, como en el caso de una página web, las hace directamente en un dispositivo de presentación tal como el monitor del usuario.
 RSS es una forma muy sencilla para que puedas recibir, directamente en tu ordenador o en una página web online (a través de un lector RSS) información actualizada sobre tus páginas web favoritas, sin necesidad de que tengas que visitarlas una a una. Esta información se actualiza automáticamente, sin que tengas que hacer nada. Para recibir las noticias RSS la página deberá tener disponible el servicio RSS y deberás tener un lector Rss.
RSS es una forma muy sencilla para que puedas recibir, directamente en tu ordenador o en una página web online (a través de un lector RSS) información actualizada sobre tus páginas web favoritas, sin necesidad de que tengas que visitarlas una a una. Esta información se actualiza automáticamente, sin que tengas que hacer nada. Para recibir las noticias RSS la página deberá tener disponible el servicio RSS y deberás tener un lector Rss.
Conclusion
Podemos concluir que XML es un lenguaje de programación web, que nos permite modificar el formato y estilo de las páginas web. XML se trata de un mecanismo para describir datos estructurados y semi-estructurados, que proporciona acceso a una rica familia de tecnologías para el tratamiento de estas informaciones. Además nos permite comunicar aplicaciones de distintas plataformas, sin que importe el origen de los datos, es decir, podríamos tener una aplicación en Linux con una base de datos Postgres y comunicarla con otra aplicación en Windows y Base de Datos MS-SQL Server.

Suscribirse a:
Comentarios (Atom)